code upload
Showing
- README.md 9 additions, 1 deletionREADME.md
- code/Experiments.ipynb 395 additions, 0 deletionscode/Experiments.ipynb
- code/blindEP_utils.py 307 additions, 0 deletionscode/blindEP_utils.py
- code/combined_view2.png 0 additions, 0 deletionscode/combined_view2.png
- code/requirements.txt 4 additions, 0 deletionscode/requirements.txt
code/Experiments.ipynb
0 → 100644
This diff is collapsed.
code/blindEP_utils.py
0 → 100644
code/combined_view2.png
0 → 100644
{kind=link}
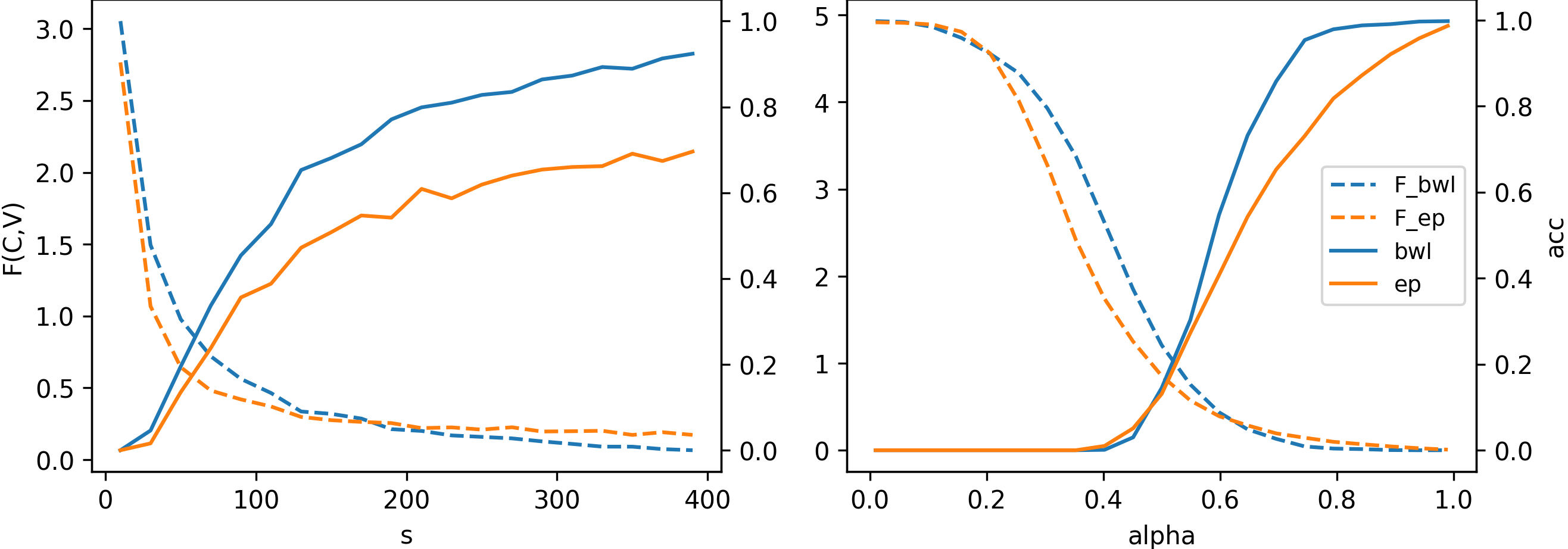
169 KiB
code/requirements.txt
0 → 100644